OCR pdf file in python on the fly
With PyMuPDF and tesserocr you can OCR image pdf easily
Requirements:
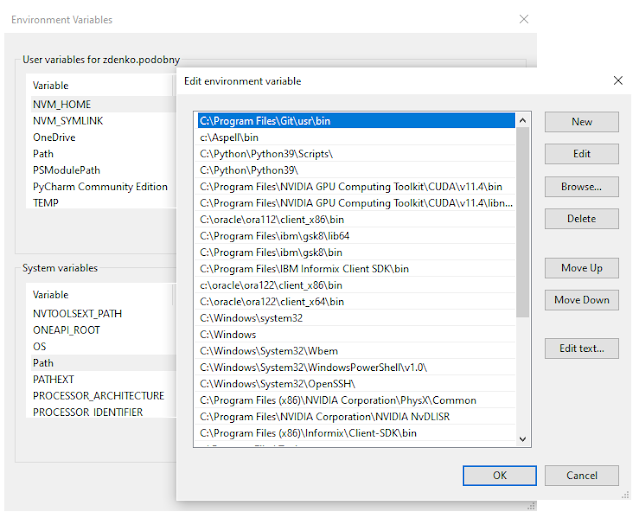
pip install PyMuPDF tesserocr
some pdf with (scanned images ;-) e.g. Tolstoy - GOD SEES THE TRUTH, BUT WAITS.pdf
Code
import fitz
import tesserocr
from PIL import Image
def get_PIL_image(pix):
"""Convert fitz pix to PIL.Image."""
img = Image.frombytes("RGB",
[pix.width, pix.height],
pix.samples)
return img
def binarize_image(image, thresh=100):
"""Custom image binarization."""
binarized = image.convert("L").convert("1")
return binarized
input_pdf = "Tolstoy - GOD SEES THE TRUTH, BUT WAITS.pdf"
output_name = "tolstoy.txt"
zoom = 2 # to increase the resolution
mat = fitz.Matrix(zoom, zoom)
doc = fitz.open(input_pdf)
ocr_api=tesserocr.PyTessBaseAPI(
path=r"tessdata_best\tessdata"
)
ocred_images = []
for page_idx, page in enumerate(doc):
pix = page.getPixmap(matrix=mat)
pil_image = get_PIL_image(pix)
binarized = binarize_image(pil_image)
print(f"OCRing page {page_idx+1} of {doc.page_count}...")
ocr_api.SetImage(pil_image)
ocred_images.append(ocr_api.GetUTF8Text())
doc.close()
ocr_api.End()
with open(output_name, mode='w', encoding='utf-8') as outfile:
for page in ocred_images:
outfile.write(page)

Comments
Post a Comment